Rst
K means Clustering 개념과 R로 구현
1. 군집분석 및 K-means algorithm의 대략적 개념
군집 분석이란?
군집 분석은 데이터들을 군집화하여 데이터의 특징을 탐색하는 데이터 분석 기법이다.
n개의 데이터 간의 유사성을 측정하고, 서로 유사한 데이터끼리 묶어나가는 과정을 거친다.
즉 군집내 유사성을 높이고, 군집간 유사성을 낮추는 방식으로 군집화를 하는것이 목적이다.
k means algorithm
unsupervised learning(unlabeld data)의 대표적 예시인 알고리즘이다.
작동 방식은 다음과 같다.
- 분류할 군집의 수 K를 정한다.
- K개의 중심점을 정한다. 이는 각 군집의 중심이 된다. 이를 기준으로 각 데이터는 자신이 가장 가까운 중심점의 군집이 된다.
- 정해진 군집의 데이터들의 평균값을 구하고 그 평균값이 군집의 중심값으로 update된다.
- update된 중심값을 이용해 각 데이터는 가장가까운 중심값인 군집으로 이동한다.
- 3, 4를 변화가 없을때까지 반복한다.
아래 그림은 위키피디아에서 설명하는 k means algorithm이다.

2. R로 K-means 적용해보기
R에선 kmeans()라는 함수를 제공한다. 이를 통해서 k-means를 적용할 수 있다.
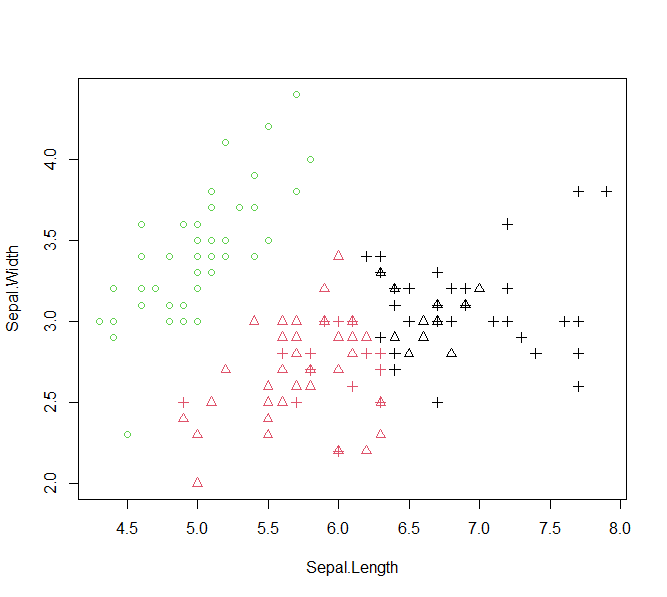
아래 코드에서는 R에서 제공하는 붓꽃의 특징을 관찰한 iris데이터셋을 이용했다.
붓꽃의 꽃받침 길이, 넓이를 이용해서 kmeans를 적용했다.
> head(iris, 2) # iris 데이터의 앞부분 2개 행을 본다.
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
> data = iris[, 1 : 2] # Petal.Length, Petal.Width 만을 가지는 데이터로 분리
> data_kmeans = kmeans(d, centers = 3) # K means 실행
> clr = data_kmeans$cluster # kmeans는 각 데이터에 대해서 cluster(군집) 번호를 부여한다.
> shape = as.numeric(iris$Species) # iris 데이터의 Species 속성을 점의 모양으로 한다.
> plot(data, col=clr, pch=shape) # 분리한 데이터를 kmean로 구한 특징을 입혀 표현한다.
Feel free to share!